Research
My research focuses on statistics related to graph-structured data. During my thesis, I developed and studied
tools for multi-scale graph comparisons as well as statistical comparisons of graphs samples, with applications
in neural networks learning.
More recently, my work lies into the filed of signal processing. I have study various aspects of graph data compression. I also exploit graph structures for applications in epidemiology and neuroscience
Publications
Preprints
|
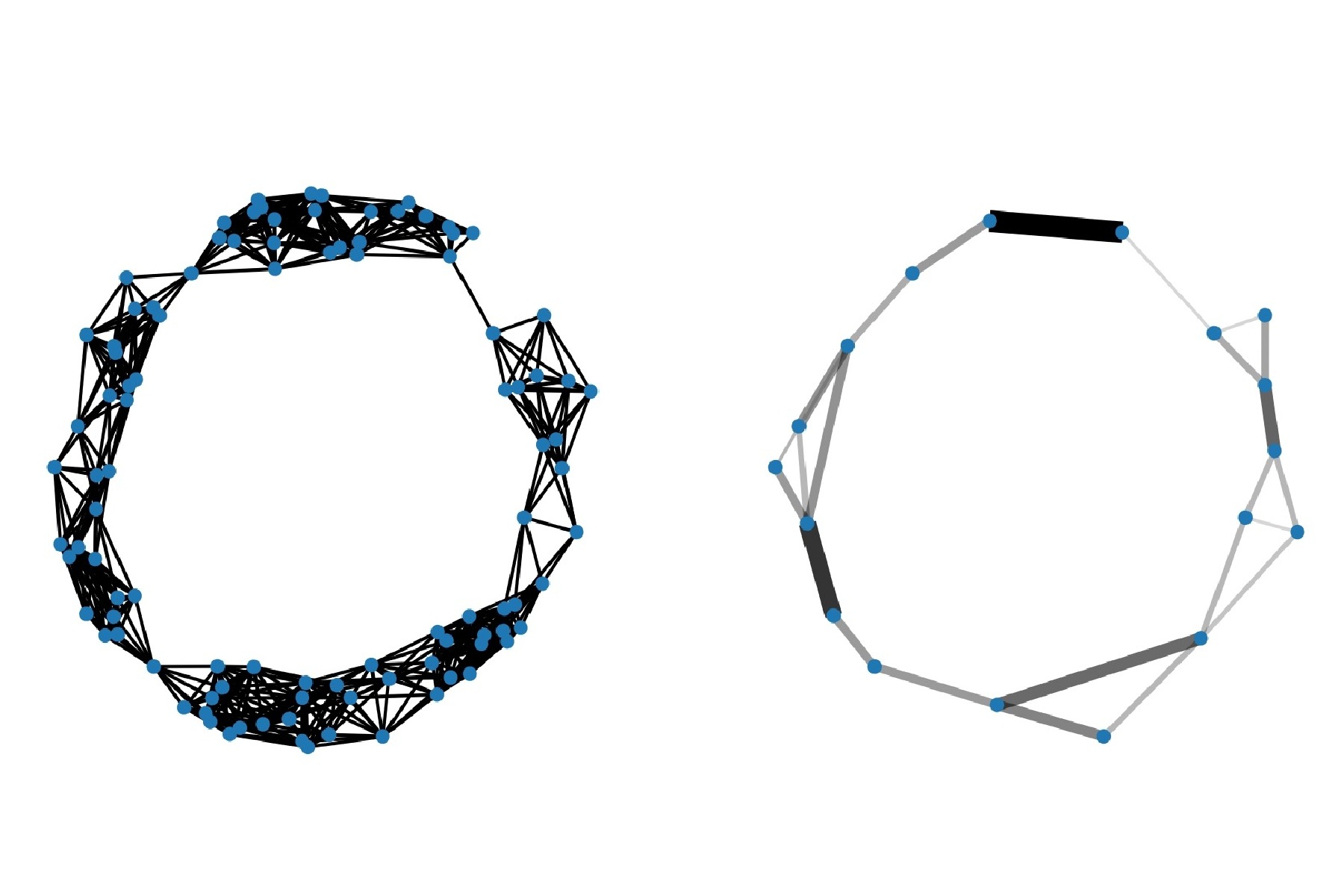
Topological spatial graph coarsening, 2025. With A Calissano [arxiv] Spatial graphs are particular graphs for which the nodes are localized in space (e.g., public transport network, molecules, branching biological structures). In this work, we consider the problem of spatial graph reduction, that aims to find a smaller spatial graph (i.e., with less nodes) with the same overall structure as the initial one. In this context, performing the graph reduction while preserving the main topological features of the initial graph is particularly relevant, due to the additional spatial information. Thus, we propose a topological spatial graph coarsening approach based on a new framework that finds a trade-off between the graph reduction and the preservation of the topological characteristics. The coarsening is realized by collapsing short edges. In order to capture the topological information required to calibrate the reduction level, we adapt the construction of classical topological descriptors made for point clouds (the so-called persistent diagrams) to spatial graphs. This construction relies on the introduction of a new filtration called triangle-aware graph filtration. Our coarsening approach is parameter-free and we prove that it is equivariant under rotations, translations and scaling of the initial spatial graph. We evaluate the performances of our method on synthetic and real spatial graphs, and show that it significantly reduces the graph sizes while preserving the relevant topological information. |
|
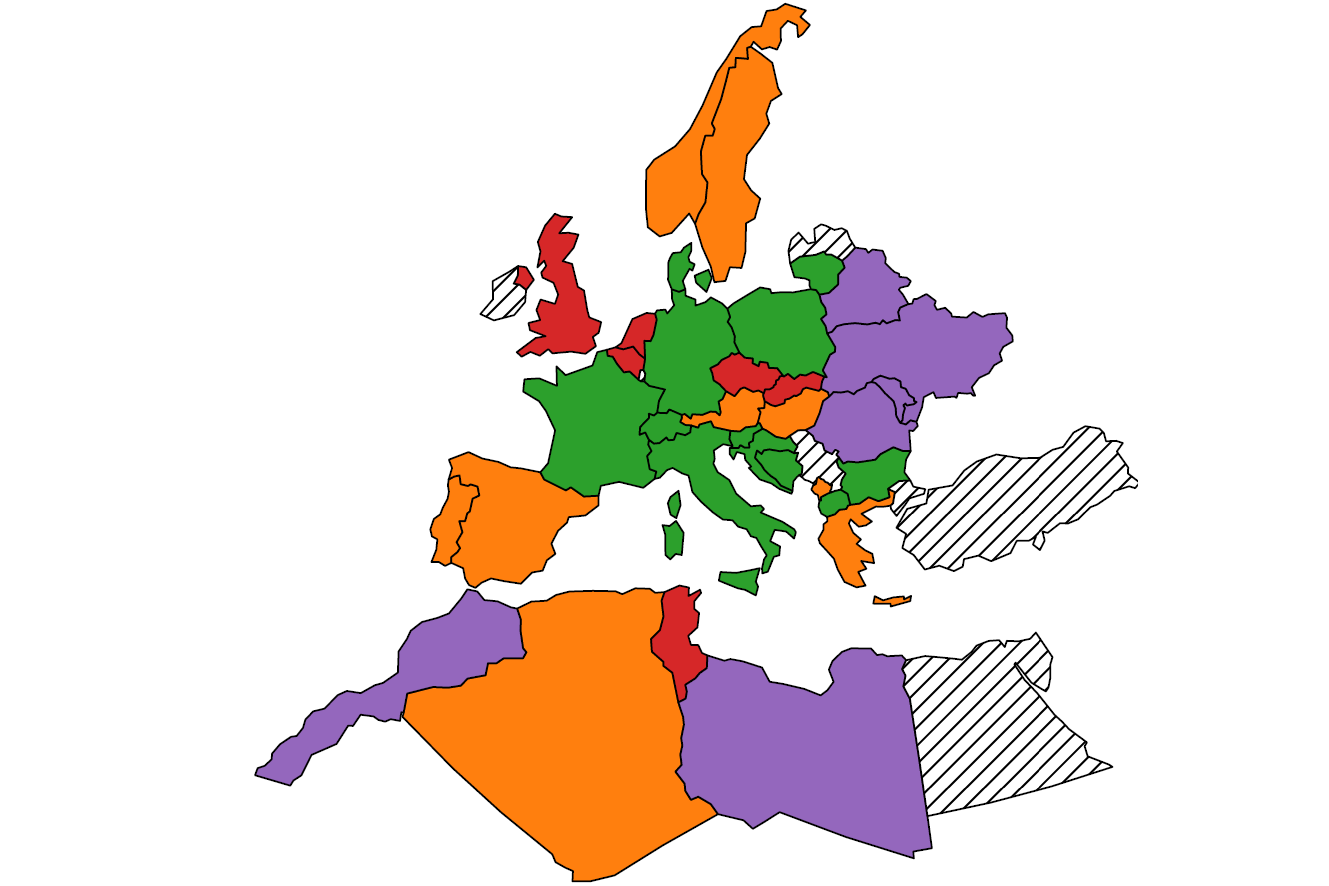
Joint reproduction number and spatial connectivity structure estimation via graph sparsity-promoting penalized functional, 2025. With B. Pascal [HAL] [arxiv] During an epidemic outbreak, decision makers crucially need accurate and robust tools to monitor the pathogen propagation. The effective reproduction number, defined as the expected number of secondary infections stemming from one contaminated individual, is a state-of-the-art indicator quantifying the epidemic intensity. Numerous estimators have been developed to precisely track the reproduction number temporal evolution. Yet, COVID-19 pandemic surveillance raised unprecedented challenges due to the poor quality of worldwide reported infection counts. When monitoring the epidemic in different territories simultaneously, leveraging the spatial structure of data significantly enhances both the accuracy and robustness of reproduction number estimates. However, this requires a good estimate of the spatial structure. To tackle this major limitation, the present work proposes a joint estimator of the reproduction number and connectivity structure. The procedure is assessed through intensive numerical simulations on carefully designed synthetic data and illustrated on real COVID-19 spatiotemporal infection counts. |
|
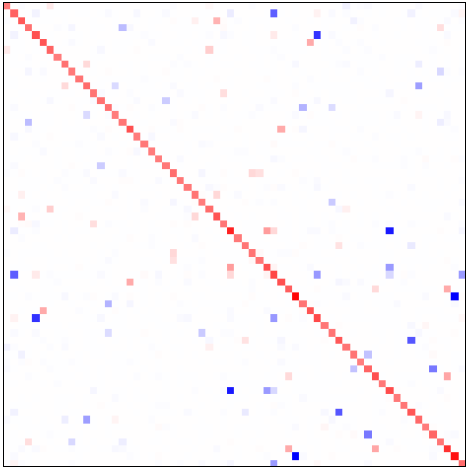
Compressive Recovery of Sparse Precision Matrices, 2023. With T. Vayer, R. Gribonval, P. Gonçalves [arxiv]
We consider the problem of learning a graph modeling the statistical relations of the \(d\) variables of a dataset with \(n\) samples \(\mathbf{X} \in \mathbb{R}^{n \times d}\).
Standard approaches amount to searching for a precision matrix \(\boldsymbol\Theta\) representative of a Gaussian graphical model that adequately explains the data.
However, most maximum likelihood-based estimators usually require storing the \(d^{2}\) values of the empirical covariance matrix, which can become prohibitive in a high-dimensional setting. |
Journal Articles

|
PASCO (PArallel Structured COarsening): an overlay to speed up graph clustering algorithms, 2025. With R. Vaudaine, T. Vayer, P. Borgnat, R. Gribonval, P. Gonçalves, M. Karsai Published in Machine Learning. [Journal] [arxiv] Clustering the nodes of a graph is a cornerstone of graph analysis and has been extensively studied. However, some popular methods are not suitable for very large graphs: e.g., spectral clustering requires the computation of the spectral decomposition of the Laplacian matrix, which is not applicable for large graphs with a large number of communities. This work introduces PASCO, an overlay that accelerates clustering algorithms. Our method consists of three steps: 1- We compute several independent small graphs representing the input graph by applying an efficient and structure-preserving coarsening algorithm. 2- A clustering algorithm is run in parallel onto each small graph and provides several partitions of the initial graph. 3- These partitions are aligned and combined with an optimal transport method to output the final partition. The PASCO framework is based on two key contributions: a novel global algorithm structure designed to enable parallelization and a fast, empirically validated graph coarsening algorithm that preserves structural properties. We demonstrate the strong performance of PASCO in terms of computational efficiency, structural preservation, and output partition quality, evaluated on both synthetic and real-world graph datasets. |

|
Eve, Adam and the Preferential Attachment Tree, 2023. With A. Contat, N. Curien, P. Lacroix and V. Rivoirard Published in Probability Theory and Related Fields. [journal] [arxiv] We consider the problem of finding the initial vertex (Adam) in a Barabasi--Albert tree process \( (\mathcal{T}(n) : n \geq 1) \) at large times. More precisely, given \( \varepsilon>0 \), one wants to output a subset \(\mathcal{P}_{ \varepsilon}(n) \) of vertices of \(\mathcal{T}(n)\) so that the initial vertex belongs to \(\mathcal{P}_ \varepsilon(n)\) with probability at least \(1- \varepsilon\) when \(n\) is large. It has been shown by Bubeck, Devroye & Lugosi (2017), refined later by Banerjee & Huang (2023), that one needs to output at least \(\varepsilon^{-1 + o(1)}\) and at most \(\varepsilon^{-2 + o(1)}\) vertices to succeed. We prove that the exponent in the lower bound is sharp and the key idea is that Adam is either a ``large degree" vertex or is a neighbor of a ``large degree" vertex (Eve). |

|
Heat diffusion distance processes: a statistically founded method to analyze graph data sets, 2023. Published in J Appl. and Comput. Topology (SI : Data Science on Graphs). [journal] [arxiv] We propose two multiscale comparisons of graphs using heat diffusion, allowing to compare graphs without node correspondence or even with different sizes. These multiscale comparisons lead to the definition of Lipschitz-continuous empirical processes indexed by a real parameter. The statistical properties of empirical means of such processes are studied in the general case. Under mild assumptions, we prove a functional Central Limit Theorem, as well as a Gaussian approximation with a rate depending only on the sample size. Once applied to our processes, these results allow to analyze data sets of pairs of graphs. We design consistent confidence bands around empirical means and consistent two-sample tests, using bootstrap methods. Their performances are evaluated by simulations on synthetic data sets. |
French Conference Papers
|
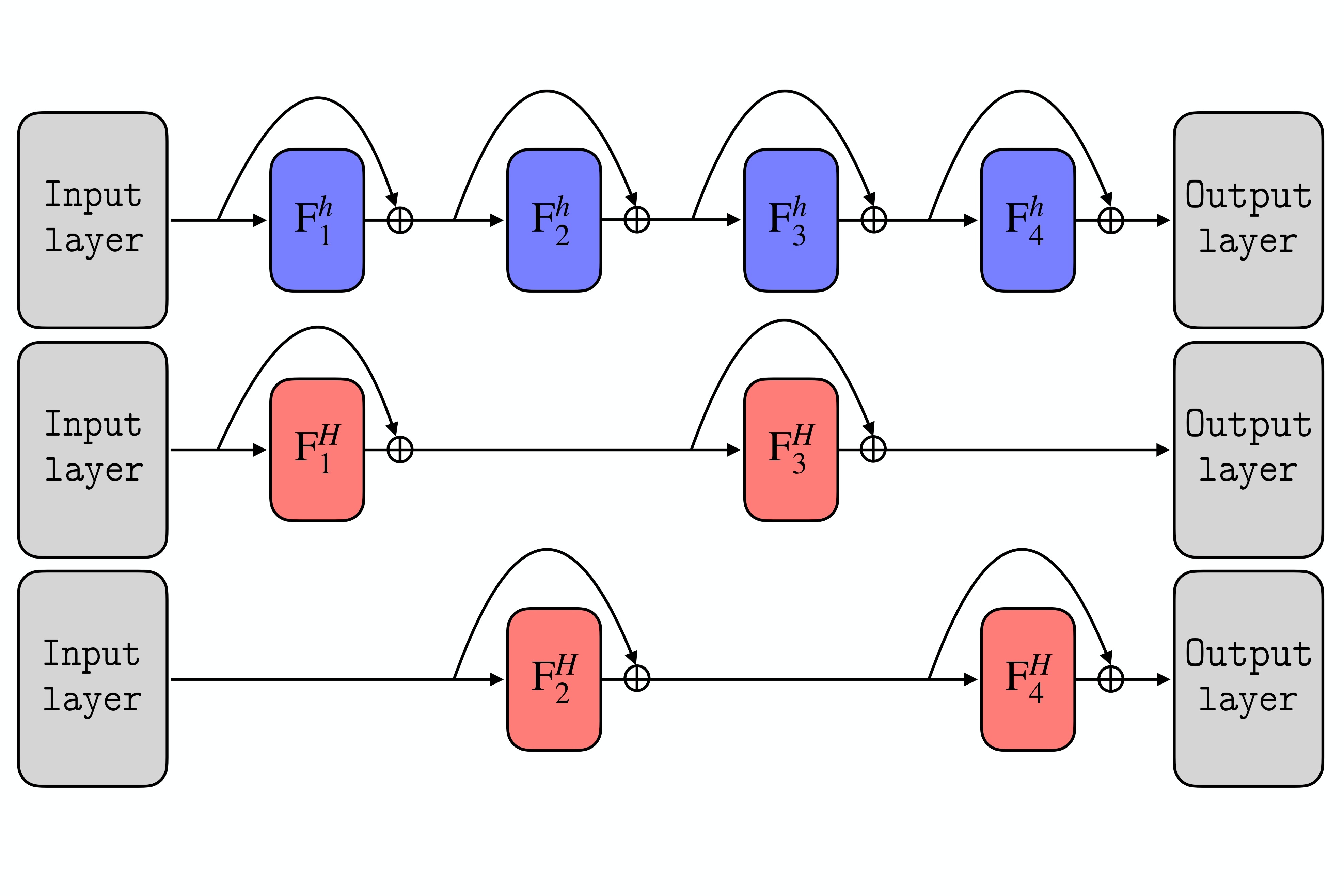
A multilevel approach to accelerate the training of Transformers, 2025. With G. Lauga, M. Chaumette, E. Desainte-Maréville and A. Lebeurrier Accepted at GRETSI 2025. [HAL] In this article, we investigate the potential of multilevel approaches to accelerate the training of transformer architectures. Using an ordinary differential equation (ODE) interpretation of these architectures, we propose an appropriate way of varying the discretization of these ODE Transformers in order to accelerate the training. We validate our approach experimentally by a comparison with the standard training procedure. |
Notes

|
A note on the relations between mixture models, maximum-likelihood and entropic optimal transport, 2025. With T. Vayer [arxiv] This note aims to demonstrate that performing maximum-likelihood estimation for a mixture model is equivalent to minimizing over the parameters an optimal transport problem with entropic regularization. The objective is pedagogical: we seek to present this already known result in a concise and hopefully simple manner. We give an illustration with Gaussian mixture models by showing that the standard EM algorithm is a specific block-coordinate descent on an optimal transport loss. |
Talks
International Conferences
- September, 2025 - Porto, Portugal - ECML 2025.
PASCO (PArallel Structured COarsening): an overlay to speed up graph clustering algorithms.
Clustering the nodes of a graph is a cornerstone of graph analysis and has been extensively studied. However, some popular methods are not suitable for very large graphs: e.g., spectral clustering requires the computation of the spectral decomposition of the Laplacian matrix, which is not applicable for large graphs with a large number of communities. This work introduces PASCO, an overlay that accelerates clustering algorithms. Our method consists of three steps: 1- We compute several independent small graphs representing the input graph by applying an efficient and structure-preserving coarsening algorithm. 2- A clustering algorithm is run in parallel onto each small graph and provides several partitions of the initial graph. 3- These partitions are aligned and combined with an optimal transport method to output the final partition. The PASCO framework is based on two key contributions: a novel global algorithm structure designed to enable parallelization and a fast, empirically validated graph coarsening algorithm that preserves structural properties. We demonstrate the strong performance of PASCO in terms of computational efficiency, structural preservation, and output partition quality, evaluated on both synthetic and real-world graph datasets. Joint work with: R. Vaudaine, T. Vayer, P. Borgnat, R. Gribonval, P. Gonçalves, M. Karsai.
- June, 2024 - Copenhagen - Popnets Workshop.
Statistical comparison of graph-structured data and its application to distribution shift detection.When working with weighted graphs, one can interpret weights as the thermal conductivity of edges. Given initial conditions, one can use the way heat diffuses to compare graphs. Choosing relevant and informative diffusion times is often essential and challenging. To circumvent this issue, we choose to take into account the whole diffusion process. We define real-valued processes indexed by [0, T] for some T > 0, representing the comparisons for all diffusion times. Using tools from topological data analysis, we are able to compare graphs with unknown node correspondence or even graphs with different sizes. In this talk, I will introduce these processes and present their statistical properties. From these results, we will see how we can construct consistent two-sample tests. Then, I will present some applications for the detection of distribution shifts in the context of neural networks by using activation graphs.
- January, 2023 - CIRM - Workshop on Random Geometry.
Finding Adam in the nearest-neighbor tree.
In this talk, I present the problem of finding the root in the online nearest-neighbor tree (NNT) model. Consider a probability distribution on some metric space. Here we will restrict ourselves to the uniform distribution on the unit circle with the Euclidean distance. The random tree is constructed recursively by linking each new node to its nearest neighbor.
Assume that we only observe the structure of such a large tree. That is, we only have access to the connectivity and neither the vertex positions in the metric space nor the vertex labels are available. Can we find a set $S$ of vertices with a reasonable size (i.e., independent of the tree size) that contain the root with high probability. I will explain how we can obtain such set by using a notion of centrality, and present the similarities and differences with the uniform random recursive tree (uRRT) model.
French Conferences
- May, 2024 - Bordeaux - Journées de Statistiques.
Compressive Recovery of Sparse Precision Matrices. - [slides]
We consider the problem of learning a graph modeling the statistical relations of the \(d\) variables of a dataset with \(n\) samples. Standard approaches amount to searching for a precision matrix representative of a Gaussian graphical model that adequately explains the data. However, most maximum likelihood-based estimators usually require storing the \(d^2\) values of the empirical covariance matrix, which can become prohibitive in a high-dimensional setting.
In this talk, we adopt a “compressive” viewpoint and aim to estimate a sparse precision matrix from a sketch of the data, i.e., a low-dimensional vector of size \(m\ll d^2\) carefully designed from the data using nonlinear random features (e.g., rank-one projections). Under certain spectral assumptions, we show that it is possible to recover the precision matrix from a sketch of size \(m=\Omega\left((d+2k)\log(d)\right)\) where \(k\) is the maximal number of edges of the underlying graph. These information-theoretic guarantees are inspired by the compressed sensing theory. We investigate the possibility of achieving practical recovery with an iterative algorithm based on the graphical lasso, viewed as a specific denoiser. We compare our approach and the graphical lasso on synthetic datasets, demonstrating its favorable performance even when the dataset is compressed.
Joint work with : Titouan Vayer, Rémi Gribonval and Paulo Gonçalves. - November, 2023 - ENS de Lyon - RT MIA Workshop: Dimension Reduction for Learning and Visualization.
Compressive Recovery of Sparse Precision Matrices.
We consider the problem of learning a graph modeling the statistical relations of the \(d\) variables of a dataset with \(n\) samples. Standard approaches amount to searching for a precision matrix representative of a Gaussian graphical model that adequately explains the data. However, most maximum likelihood-based estimators usually require storing the \(d^2\) values of the empirical covariance matrix, which can become prohibitive in a high-dimensional setting.
In this talk, we adopt a “compressive” viewpoint and aim to estimate a sparse precision matrix from a sketch of the data, i.e., a low-dimensional vector of size \(m\ll d^2\) carefully designed from the data using nonlinear random features (e.g., rank-one projections). Under certain spectral assumptions, we show that it is possible to recover the precision matrix from a sketch of size \(m=\Omega\left((d+2k)\log(d)\right)\) where \(k\) is the maximal number of edges of the underlying graph. These information-theoretic guarantees are inspired by the compressed sensing theory. We investigate the possibility of achieving practical recovery with an iterative algorithm based on the graphical lasso, viewed as a specific denoiser. We compare our approach and the graphical lasso on synthetic datasets, demonstrating its favorable performance even when the dataset is compressed.
Joint work with : Titouan Vayer, Rémi Gribonval and Paulo Gonçalves. - June, 2022 - Lyon - Journées de Statistiques de la SFdS.
Analyse statistique de graphes, via des processus de diffusion de la chaleur.
Ce travail porte sur la comparaison de données de graphes, potentiellement pondérés et de tailles différentes. Lorsqu’on travaille avec des graphes pondérés, on peut interpréter les poids des arêtes comme des conductivités thermiques. Dès lors, on peut comparer les graphes en comparant leur répartition de chaleur après un temps de diffusion t. Ce paramètre d’échelle t doit être minutieusement choisi pour s’assurer des comparaisons pertinentes. A l’opposé de précédents travaux considérant un temps de diffusion fixé arbitrairement ou choisi à partir des données, on propose de prendre en compte tout le processus de diffusion. Pour cela, on définit des processus à valeurs réelles indexés par tous les temps de diffusion dans (0,T), en concaténant les comparaisons faites aux différentes échelles. Dans cet exposé, nous commencerons par présenter ces processus de comparaison de graphes et leurs propriétés statistiques. Puis, nous montrerons comment en dériver des tests à deux échantillons consistants. Nous présenterons quelques applications sur des jeux de données synthétiques et réels. On s’intéressera notamment aux données provenant de graphes d’activations de réseaux de neurones.
- Oct, 2021 - île d'Oléron - Colloque Jeunes Probabilistes et Statisticiens.
Statistical analysis of graph structured data, via heat diffusion processes. - [slides]
When working with weighted graphs, one can interpret weights as the thermal conductivity of edges. This means that heat diffuses faster along edges with higher weights. Given initial conditions, one can use the way heat diffuses to compare graphs. But choosing a relevant and informative diffusion time is often essential and challenging. To circumvent this issue, we choose to take into account the whole diffusion process. For that, we define real-valued processes indexed by all the diffusion times in [0, T] for some T > 0, namely the Heat Kernel Distance (HKD) process and the Heat Persistence Distance (HPD) process. Borrowing tools from TDA, the HPD process is able to compare graphs without known node correspondence or even graphs with different sizes. In this talk, I will introduce these processes and present their statistical properties. Namely, we proved under mild assumptions that they verify a functional central limit theorem and admit a gaussian approximation. Moreover, I will present potential applications of these processes (the construction of confidence bands and two-sample tests).
- Dec, 2021 - Besançon - Forum des Jeunes Mathématicien.ne.s.
Statistical analysis of graph structured data, via heat diffusion processes. - [slides]
When working with weighted graphs, one can interpret weights as the thermal conductivity of edges. This means that heat diffuses faster along edges with higher weights. Given initial conditions, one can use the way heat diffuses to compare graphs. But choosing a relevant and informative diffusion time is often essential and challenging. To circumvent this issue, we choose to take into account the whole diffusion process. For that, we define real-valued processes indexed by all the diffusion times in [0, T] for some T > 0, namely the Heat Kernel Distance (HKD) process and the Heat Persistence Distance (HPD) process. Borrowing tools from TDA, the HPD process is able to compare graphs without known node correspondence or even graphs with different sizes. In this talk, I will introduce these processes and present their statistical properties. Namely, we proved under mild assumptions that they verify a functional central limit theorem and admit a gaussian approximation. Moreover, I will present potential applications of these processes (the construction of confidence bands and two-sample tests).
Invited Seminars
- November, 2025 - Angers, France - Séminaire de probabilités et statistique.
Joint reproduction number and spatial connectivity structure estimation via graph sparsity-promoting penalized functional.
During an epidemic outbreak, decision makers crucially need accurate and robust tools to monitor the pathogen propagation. The effective reproduction number, defined as the expected number of secondary infections stemming from one contaminated individual, is a state-of-the-art indicator quantifying the epidemic intensity. Numerous estimators have been developed to precisely track the reproduction number temporal evolution. Yet, COVID-19 pandemic surveillance raised unprecedented challenges due to the poor quality of worldwide reported infection counts. When monitoring the epidemic in different territories simultaneously, leveraging the spatial structure of data significantly enhances both the accuracy and robustness of reproduction number estimates. However, this requires a good estimate of the spatial structure. To tackle this major limitation, the present work proposes a joint estimator of the reproduction number and connectivity structure. The procedure is assessed through intensive numerical simulations on carefully designed synthetic data and illustrated on real COVID-19 spatiotemporal infection counts. Joint work with Barbara Pascal.
- April, 2025 - Paris - Séminaire Parisien de Statistiques.
Compressive Recovery of Sparse Precision Matrices.
We consider the problem of learning a graph modeling the statistical relations of the \(d\) variables of a dataset with \(n\) samples. Standard approaches amount to searching for a precision matrix representative of a Gaussian graphical model that adequately explains the data. However, most maximum likelihood-based estimators usually require storing the \(d^2\) values of the empirical covariance matrix, which can become prohibitive in a high-dimensional setting.
In this talk, we adopt a “compressive” viewpoint and aim to estimate a sparse precision matrix from a sketch of the data, i.e., a low-dimensional vector of size \(m\ll d^2\) carefully designed from the data using nonlinear random features (e.g., rank-one projections). Under certain spectral assumptions, we show that it is possible to recover the precision matrix from a sketch of size \(m=\Omega\left((d+2k)\log(d)\right)\) where \(k\) is the maximal number of edges of the underlying graph. These information-theoretic guarantees are inspired by the compressed sensing theory. We investigate the possibility of achieving practical recovery with an iterative algorithm based on the graphical lasso, viewed as a specific denoiser. We compare our approach and the graphical lasso on synthetic datasets, demonstrating its favorable performance even when the dataset is compressed.
Joint work with : Titouan Vayer, Rémi Gribonval and Paulo Gonçalves. - April, 2025 - Nantes - Applied mathematics seminar, LMJL.
Compressive Recovery of Sparse Precision Matrices.
We consider the problem of learning a graph modeling the statistical relations of the \(d\) variables of a dataset with \(n\) samples. Standard approaches amount to searching for a precision matrix representative of a Gaussian graphical model that adequately explains the data. However, most maximum likelihood-based estimators usually require storing the \(d^2\) values of the empirical covariance matrix, which can become prohibitive in a high-dimensional setting.
In this talk, we adopt a “compressive” viewpoint and aim to estimate a sparse precision matrix from a sketch of the data, i.e., a low-dimensional vector of size \(m\ll d^2\) carefully designed from the data using nonlinear random features (e.g., rank-one projections). Under certain spectral assumptions, we show that it is possible to recover the precision matrix from a sketch of size \(m=\Omega\left((d+2k)\log(d)\right)\) where \(k\) is the maximal number of edges of the underlying graph. These information-theoretic guarantees are inspired by the compressed sensing theory. We investigate the possibility of achieving practical recovery with an iterative algorithm based on the graphical lasso, viewed as a specific denoiser. We compare our approach and the graphical lasso on synthetic datasets, demonstrating its favorable performance even when the dataset is compressed.
Joint work with : Titouan Vayer, Rémi Gribonval and Paulo Gonçalves. - March, 2025 - Rennes - Statistics seminar, IRMAR.
Compressive Recovery of Sparse Precision Matrices.
We consider the problem of learning a graph modeling the statistical relations of the \(d\) variables of a dataset with \(n\) samples. Standard approaches amount to searching for a precision matrix representative of a Gaussian graphical model that adequately explains the data. However, most maximum likelihood-based estimators usually require storing the \(d^2\) values of the empirical covariance matrix, which can become prohibitive in a high-dimensional setting.
In this talk, we adopt a “compressive” viewpoint and aim to estimate a sparse precision matrix from a sketch of the data, i.e., a low-dimensional vector of size \(m\ll d^2\) carefully designed from the data using nonlinear random features (e.g., rank-one projections). Under certain spectral assumptions, we show that it is possible to recover the precision matrix from a sketch of size \(m=\Omega\left((d+2k)\log(d)\right)\) where \(k\) is the maximal number of edges of the underlying graph. These information-theoretic guarantees are inspired by the compressed sensing theory. We investigate the possibility of achieving practical recovery with an iterative algorithm based on the graphical lasso, viewed as a specific denoiser. We compare our approach and the graphical lasso on synthetic datasets, demonstrating its favorable performance even when the dataset is compressed.
Joint work with : Titouan Vayer, Rémi Gribonval and Paulo Gonçalves. - February, 2025 - Marne la Vallée - Proba-Stats seminar of the LAMA team.
Compressive Recovery of Sparse Precision Matrices.
We consider the problem of learning a graph modeling the statistical relations of the \(d\) variables of a dataset with \(n\) samples. Standard approaches amount to searching for a precision matrix representative of a Gaussian graphical model that adequately explains the data. However, most maximum likelihood-based estimators usually require storing the \(d^2\) values of the empirical covariance matrix, which can become prohibitive in a high-dimensional setting.
In this talk, we adopt a “compressive” viewpoint and aim to estimate a sparse precision matrix from a sketch of the data, i.e., a low-dimensional vector of size \(m\ll d^2\) carefully designed from the data using nonlinear random features (e.g., rank-one projections). Under certain spectral assumptions, we show that it is possible to recover the precision matrix from a sketch of size \(m=\Omega\left((d+2k)\log(d)\right)\) where \(k\) is the maximal number of edges of the underlying graph. These information-theoretic guarantees are inspired by the compressed sensing theory. We investigate the possibility of achieving practical recovery with an iterative algorithm based on the graphical lasso, viewed as a specific denoiser. We compare our approach and the graphical lasso on synthetic datasets, demonstrating its favorable performance even when the dataset is compressed.
Joint work with : Titouan Vayer, Rémi Gribonval and Paulo Gonçalves. - December, 2024 - Rennes - COMPACT seminar.
Compressive Recovery of Sparse Precision Matrices.
We consider the problem of learning a graph modeling the statistical relations of the \(d\) variables of a dataset with \(n\) samples. Standard approaches amount to searching for a precision matrix representative of a Gaussian graphical model that adequately explains the data. However, most maximum likelihood-based estimators usually require storing the \(d^2\) values of the empirical covariance matrix, which can become prohibitive in a high-dimensional setting.
In this talk, we adopt a “compressive” viewpoint and aim to estimate a sparse precision matrix from a sketch of the data, i.e., a low-dimensional vector of size \(m\ll d^2\) carefully designed from the data using nonlinear random features (e.g., rank-one projections). Under certain spectral assumptions, we show that it is possible to recover the precision matrix from a sketch of size \(m=\Omega\left((d+2k)\log(d)\right)\) where \(k\) is the maximal number of edges of the underlying graph. These information-theoretic guarantees are inspired by the compressed sensing theory. We investigate the possibility of achieving practical recovery with an iterative algorithm based on the graphical lasso, viewed as a specific denoiser. We compare our approach and the graphical lasso on synthetic datasets, demonstrating its favorable performance even when the dataset is compressed.
Joint work with : Titouan Vayer, Rémi Gribonval and Paulo Gonçalves. - November, 2024 - Rennes - Malt seminar.
Statistical comparison of graph-structured data and its application to distribution shift detection.When working with weighted graphs, one can interpret weights as the thermal conductivity of edges. Given initial conditions, one can use the way heat diffuses to compare graphs. Choosing relevant and informative diffusion times is often essential and challenging. To circumvent this issue, we choose to take into account the whole diffusion process. We define real-valued processes indexed by [0, T] for some T > 0, representing the comparisons for all diffusion times. Using tools from topological data analysis, we are able to compare graphs with unknown node correspondence or even graphs with different sizes. In this talk, I will introduce these processes and present their statistical properties. From these results, we will see how we can construct consistent two-sample tests. Then, I will present some applications for the detection of distribution shifts in the context of neural networks by using activation graphs.
- September, 2024 - Nantes - SIMS seminar.
Compressive Recovery of Sparse Precision Matrices.
We consider the problem of learning a graph modeling the statistical relations of the \(d\) variables of a dataset with \(n\) samples. Standard approaches amount to searching for a precision matrix representative of a Gaussian graphical model that adequately explains the data. However, most maximum likelihood-based estimators usually require storing the \(d^2\) values of the empirical covariance matrix, which can become prohibitive in a high-dimensional setting.
In this talk, we adopt a “compressive” viewpoint and aim to estimate a sparse precision matrix from a sketch of the data, i.e., a low-dimensional vector of size \(m\ll d^2\) carefully designed from the data using nonlinear random features (e.g., rank-one projections). Under certain spectral assumptions, we show that it is possible to recover the precision matrix from a sketch of size \(m=\Omega\left((d+2k)\log(d)\right)\) where \(k\) is the maximal number of edges of the underlying graph. These information-theoretic guarantees are inspired by the compressed sensing theory. We investigate the possibility of achieving practical recovery with an iterative algorithm based on the graphical lasso, viewed as a specific denoiser. We compare our approach and the graphical lasso on synthetic datasets, demonstrating its favorable performance even when the dataset is compressed.
Joint work with : Titouan Vayer, Rémi Gribonval and Paulo Gonçalves. - May, 2023 - LJK Grenoble - Seminar of the DATA department.
Statistical comparison of graph-structured data and its application to distribution shift detection.
When working with weighted graphs, one can interpret weights as the thermal conductivity of edges. Given initial conditions, one can use the way heat diffuses to compare graphs. Choosing relevant and informative diffusion times is often essential and challenging. To circumvent this issue, we choose to take into account the whole diffusion process. We define real-valued processes indexed by [0, T] for some T > 0, representing the comparisons for all diffusion times. Using tools from topological data analysis, we are able to compare graphs with unknown node correspondence or even graphs with different sizes.
In this talk, I will introduce these processes and present their statistical properties. From these results, we will see how we can construct consistent two-sample tests. Then I will present some applications to the detection of distribution shifts in the context of neural networks by using activation graphs. - January, 2023 - Campus Agro Paris-Saclay - Meeting of the EcoNet project.
Statistical comparison of graph structured data.
Not provided.
- November, 2022 - Orsay - Working group of the Probability-Statistics team.
Testing between the stochastic block model and the Erdos-Renyi model. [article].
With Leonardo Martins-Bianco and Zacharie Naulet.
In a first part, we talk about the detection of the SBM vs ER model, in the sparse case, in the regime where detection is possible. We show that by counting cycles we can distinguish between the two models. Then, we talk about finding the communities in an SBM graph. We present the spectral clustering algorithm and show that it is efficient in the dense case.
- June, 2022 - Lyon - Machine Learning and Signal Processing Seminar.
Heat diffusion distance processes for graphs and their application to distribution shift detection.
When working with weighted graphs, one can interpret weights as the thermal conductivity of edges. Given initial conditions, one can use the way heat diffuses to compare graphs. Choosing relevant and informative diffusion times is often essential and challenging. To circumvent this issue, we choose to take into account the whole diffusion process. We define real-valued processes indexed by [0, T] for some T > 0, representing the comparisons for all diffusion times. Using tools from topological data analysis, we are able to compare graphs with unknown node correspondence or even graphs with different sizes.
In this talk, I will introduce these processes and present their statistical properties. From these results, we will see how we can construct consistent two-sample tests. Then I will present some applications to the detection of distribution shifts in the context of neural networks by using activation graphs. - June, 2022 - Orsay - Celeste seminar.
Heat diffusion distance processes for graphs and their application to distribution shift detection.
When working with weighted graphs, one can interpret weights as the thermal conductivity of edges. Given initial conditions, one can use the way heat diffuses to compare graphs. Choosing relevant and informative diffusion times is often essential and challenging. To circumvent this issue, we choose to take into account the whole diffusion process. We define real-valued processes indexed by [0, T] for some T > 0, representing the comparisons for all diffusion times. Using tools from topological data analysis, we are able to compare graphs with unknown node correspondence or even graphs with different sizes.
In this talk, I will introduce these processes and present their statistical properties. From these results, we will see how we can construct consistent two-sample tests. Then I will present some applications to the detection of distribution shifts in the context of neural networks by using activation graphs. - May, 2022 - Orsay - Working group of the Probability-Statistics team.
Presentation of Density estimation from unweighted k-nearest neighbor graphs: a roadmap [article].
With Alice Contat and Nicolas Curien.
Consider a density f on R^d, and some i.i.d. sample of size n following this density. Construct the oriented k-nearest neighbor graph. Can we, only from the graph structure (i.e. forgetting the embedding in R^d), recover the density. We study the 1D case in details. In particular, we explained why the order of magnitude of k needs to be greater than n^(2/3). We proposed some potential improvements of the proposed method for d=1.
- May, 2022 - Porquerolles - Datashape seminar.
Detecting distribution shifts using activation graphs from neural networks.
The abstract is not available yet.
- Mar, 2022 - Orsay - Working group of the Probability-Statistics team.
Presentation of Identifying the deviator [arxiv].
Alice and Bob are playing a game. They construct a binary sequence by alternatively anouncing 0 or 1. Imagine that a rule says that they should announce their digit by following a Bernoulli distribution of parameter 1/2, independently of the past of the sequence. If they both follow the rule, the sequence will verify several properties. For example, A : the proportion of 1s in the sequence tends to 1/2 ; B : the associated random walk (where we make a +1 step when a player announced 1 and a -1 step when a player announced 0) will cross 0 infinitely many times. Assuming that A or B is not observed, and that only one of the players is cheating, I present the article's results that show how we can identify the cheater almost surely, given the whole binary sequence. The article actually tackles a more general problem, but I only focus on these two examples.
- Oct, 2021 - Orsay - Working group of the Probability-Statistics team.
Presentation of Finding Adam in random growing trees [article].
The article deals with the estimation of the root when observing the structure of a large tree following random recursive tree models : either the uniform attachment model or the preferential attachment model. I only presented the results for the uniform attachment model. The weaker result shows that the root is recovered with probability greater than 1-ε, when the set of candidates for the root is of polynomial size in 1/ε, where the candidates are chosen as the ones whose largest subtree is the smallest. The strongest result shows that set of candidates can be chosen with subpolynomial size, by looking at a more refined statistic. I presented both results and the proof of the weaker one.
- Oct, 2021 - U. Paris-Saclay - Datashape seminar
Heat diffusion distance processes: a statistically founded method to analyze graph data sets. - [slides]
When working with weighted graphs, one can interpret weights as the thermal conductivity of edges. This means that heat diffuses faster along edges with higher weights. Given initial conditions, one can use the way heat diffuses to compare graphs. But choosing a relevant and informative diffusion time is often essential and challenging. To circumvent this issue, we choose to take into account the whole diffusion process. For that, we define real-valued processes indexed by all the diffusion times in [0, T] for some T > 0, namely the Heat Kernel Distance (HKD) process and the Heat Persistence Distance (HPD) process. Borrowing tools from TDA, the HPD process is able to compare graphs without known node correspondence or even graphs with different sizes. In this talk, I will introduce these processes and present their statistical properties. Namely, we proved under mild assumptions that they verify a functional central limit theorem and admit a gaussian approximation. Moreover, I will present potential applications of these processes (the construction of confidence bands and two-sample tests, the study of neural networks through their activation graphs).
- Mar, 2021 - U. Paris-Saclay - vulgarization seminar
Gaussian approximations for random functions. - [slides]
The Central Limit Theorem indicates that a properly rescaled sum of random variables converges in distribution to a gaussian distribution. This is where the gaussian approximation problem arises : is it possible to draw these random variables, as well as a gaussian variable, such that the rescaled sum and the gaussian variable are close?
The presentation starts by a few reminders concerning standard probability results : law of large numbers, central limit theorem, Berry-Essen theorem, and quantile transformation. Then, historical results on gaussian approximation are presented. It includes, for the real case, the Skorokhod embedding and the Komlos Major and Tusnady (KMT) approach, as well as Zaitsev's results for the multidimensional case and Koltchinskii's results for general empirical processes. The end of this presentation concerns my thesis subject and its link with the gaussian approximation problem for random functions.
Material
- My Ph.D. thesis is entitled Contributions to statistical analysis of graph-structured data.
You can find the manuscript and the slides of the defense here : [manuscript] [slides].
Others
Editorial activities
- 2025 - Reviewing activity for ALEA.
- 2025 - Review for the GRETSI 2025 conference.
- 2024 - Reviewing activity for the Bernoulli Journal.
- 2023 - Review for the GRETSI 2025 conference,
Special session: Graph Learning and Learning with Graphs.
Awards
- Winner of the challenge : Mathématiques et Entreprises 2021, with Olympio Hacquart and Vadim Lebovici.
Subject proposed by french company Eurecam : Reconstruction of trajectories from real life 3D detections of people. We choose to use optimal transport with boundary to reconstruct trajectories frame by frame. We proposed an ad hoc minimization problem. Pre-processing and post-processing steps were implemented to obtain better reconstructions. Our work can be found here.